FFD:Face Forgery Detection
شناسایی جعل چهرهFFD:Face Forgery Detection
شناسایی جعل چهرهمثال 1: فشردهسازی و بازسازی تصاویر کاراکترهای دستنویس با Autoencoder
مسئله و هدف
در این مثال، قصد داریم از یک Autoencoder عمیق برای کاهش ابعاد تصاویر کاراکترهای دستنویس مانند الفبای فارسی، عربی، یا انگلیسی و بازسازی آنها با حداقل اتلاف اطلاعات استفاده کنیم. این روش میتواند در کاربردهایی مانند OCR تشخیص کاراکتر نوری و بهینهسازی حافظه در سیستمهای نهفته مؤثر باشد.
اهداف:
- کاهش ابعاد کاراکترهای دستنویس از تصاویر ۲۸×۲۸ به فضای فشرده
- تحلیل ساختار نهفتهی کاراکترها در فضای کمبعد
- بازسازی دقیق کاراکتر از نمایش فشردهی آن
معماری مدل Autoencoder
یک Autoencoder کلاسیک شامل دو بخش است:
کدگذار (Encoder)
- کاراکتر دستنویس ورودی را دریافت کرده و آن را به یک نمایش فشردهشده در یک فضای ۲ بعدی یا ۱۰ بعدی نگاشت میکند.
- هدف این بخش، استخراج ویژگیهای مهم و حذف اطلاعات اضافی است.
کدگشا (Decoder)
- از فضای فشردهی حاصل، تصویر اصلی را بازسازی میکند.
- باید تا حد امکان، ساختار و جزئیات اصلی کاراکترها را حفظ کند.
فرمولسازی ریاضی مدل
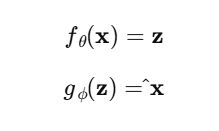
که در آن:
- θf یک کدگذار با وزنهای θ است که داده ورودی را به فضای فشرده نگاشت میکند.
- Φg یک کدگشا با وزنهای ϕ است که داده فشردهشده را به تصویر اولیه بازمیگرداند.
- Z نمایش فشردهی کاراکتر در فضای نهفته است.
- ^ x خروجی بازسازیشده است.
پیادهسازی مدل با Keras و TensorFlow
import tensorflow as tf
from tensorflow.keras.layers import Dense, Input, Flatten, Reshape
from tensorflow.keras.models import Model
import matplotlib.pyplot as plt
import numpy as np
# تعریف ورودی (تصویر 28×28)
input_layer = Input(shape=(28, 28, 1))
# کدگذار (Encoder) – فشردهسازی دادهها
x = Flatten()(input_layer)
x = Dense(256, activation='relu')(x)
x = Dense(128, activation='relu')(x)
latent = Dense(10, activation='linear', name='latent_space')(x)
# فضای نهفته 10 بعدی
# کدگشا (Decoder) – بازسازی تصویر
x = Dense(128, activation='relu')(latent)
x = Dense(256, activation='relu')(x)
x = Dense(28 * 28, activation='sigmoid')(x)
output_layer = Reshape((28, 28, 1))(x)
# مدل Autoencoder
autoencoder = Model(input_layer, output_layer)
autoencoder.compile(optimizer='adam', loss='mse')
print(autoencoder.summary())
آموزش مدل و تست عملکرد
پس از تعریف مدل، آن را با دادههای کاراکترهای دستنویس آموزش میدهیم. در اینجا از دیتاست EMNIST (مجموعهای از حروف دستنویس انگلیسی) استفاده میکنیم.
from tensorflow.keras.datasets import mnist
# بارگذاری دادهها
(X_train, _), (X_test, _) = mnist.load_data()
X_train = X_train.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0
X_train = np.expand_dims(X_train, axis=-1)
X_test = np.expand_dims(X_test, axis=-1)
# آموزش مدل
autoencoder.fit(X_train, X_train, epochs=20, batch_size=128, validation_data=(X_test, X_test))
تحلیل و تفسیر فضای نهفتهی کاراکترها
پس از آموزش، مدل میتواند کاراکترهای دستنویس را به یک فضای فشرده نگاشت کند. در ادامه، این فضای نهفته را بصریسازی میکنیم.
# استخراج کدگذار و نمایش فضای فشرده
encoder = Model(input_layer, latent)
X_encoded = encoder.predict(X_test)
plt.scatter(X_encoded[:, 0], X_encoded[:, 1], alpha=0.5, cmap='jet')
plt.colorbar()
plt.xlabel('Latent Dimension 1')
plt.ylabel('Latent Dimension 2')
plt.title('Projection of Handwritten Characters in 2D Space')
plt.show()
این تصویر نشان میدهد که کاراکترهای
مشابه، در فضای فشرده به هم نزدیک هستند.
مدل یاد گرفته است که ویژگیهای مهم
کاراکترها را استخراج کند.
بازسازی نمونهای از کاراکترهای دستنویس
# تولید تصاویر بازسازیشده
decoded_imgs = autoencoder.predict(X_test)
# نمایش تصاویر اصلی و بازسازیشده
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# تصویر اصلی
ax = plt.subplot(2, n, i + 1)
plt.imshow(X_test[i].reshape(28, 28), cmap="gray")
plt.axis("off")
# تصویر بازسازیشده
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28), cmap="gray")
plt.axis("off")
plt.show()
اگر مدل بهدرستی آموزش دیده باشد، تصاویر بازسازیشده باید بسیار شبیه به نمونههای اصلی باشند.
چرا از فضای فشرده برای کاراکترهای دستنویس استفاده کنیم؟
· کاهش حجم دادهها: میتوان به جای ذخیره تصویر، فقط مختصات فضای فشرده را ذخیره کرد.
· افزایش دقت تشخیص کاراکتر: در OCR، فضای فشرده میتواند دادههای اضافی را حذف کرده و ویژگیهای مهم را حفظ کند.
· تحلیل خوشهبندی کاراکترها: در فضای فشرده، حروف مشابه (مثلاً o و c) به هم نزدیک خواهند بود.
کاربردهای عملی Autoencoder در پردازش کاراکترهای دستنویس
تشخیص خودکار کاراکترها (OCR): استخراج
ویژگیهای مهم از کاراکترها برای تشخیص بهتر.
سیستمهای فشردهسازی متن و تصویر: کاهش
حجم دادههای کاراکتر دستنویس بدون از دست دادن اطلاعات مهم.
تحلیل خوشهای کاراکترها: گروهبندی
و خوشهبندی حروف مختلف در یک فضای معنیدار.
نتیجه نهایی: Autoencoder میتواند کاراکترهای دستنویس را فشرده کند و سپس آنها را با دقت بالا بازسازی کند، که در OCR و سایر سیستمهای پردازش متن کاربردهای فراوانی دارد!


























